ReRAM and In-memory Computing-Based Accelerator for Deep Neural Networks
Talha Bin Azmat (Team Leader)
Bilal Shabbir
This proposal proposes the design of a high-speed accelerator that uses Resistive Random Access Memory (ReRAM) cells to perform analog computation. The accelerator will implement convolution neural networks or deep neural networks. The design is inspired by the reference paper [1]. The design of this accelerator has many advantages over conventional digital accelerators. The architecture yields improvements of 14.8×, 5.5×, and 7.5× in throughput, energy, and computational density respectively, over the state-of-the-art design.
Many recent efforts have been made to design accelerators for popular machine learning algorithms, such as those involving convolutional and deep neural networks (CNNs and DNNs). These algorithms typically involve a large number of multiply-accumulate (MAC) operations. The bulk of the operation of these accelerators consists of these MAC operations. The purpose of designing these accelerators is to speed up these MAC operations so we can have lower inference times.
Typically, MAC operations are performed using adders. But recently advancements in technology have allowed us to use analog computation for speeding up these operations. Figure 1 explains how the addition and multiplication of vectors is made possible through Analog computation. This crossbar structure performs the 4x1 vector multiplication with a 4x4 matrix. This calculation is instant as there is no delay element in this structure. V represents the inout vectors and W represents the weights of the matrix. I is the ouput after multiplication
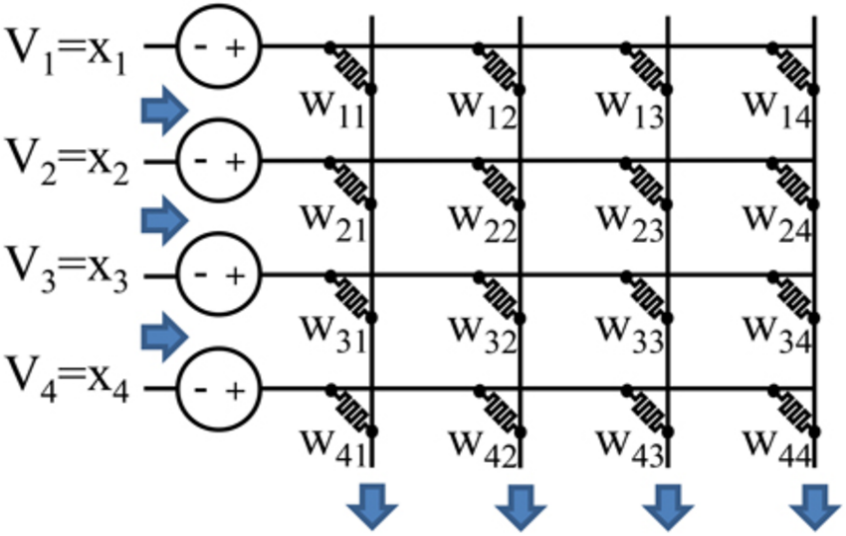
Figure 1: Crossbar architecture for matrix multiplication using analog in-memory-computation
As seen in figure 2, we first convert our digital data into an analog signal using a DAC. After the signal is processed in the analog domain, it will reach a Sample and Hold circuit (S&H). The S&H circuit is used here to enable pipelining. The signal is then sent to an ADC where it is then converted back to a digital domain so that it can be read by the processor.

Figure 2: ReRAM crossbar with ADC and DAC (MAC unit)
To design our accelerators, we will use multiple vector-multiplication matrix cells and combine them to realize a single tile for our accelerator as shown in Figure 3. We will then combine the tiles to realize the whole accelerator chip. The accelerator will then be to the RISC-V processor, enabling us to load any popular algorithm on our chip.

Figure 3 Block diagram for a single layer of the accelerator.
DRAM: Dynamic Random Access Memory, OR: Output Register, S + A: Shift and Add unit

Figure 4The block diagram for the accelerator chip
The project has a lot of room for novelty. There are many different ways and methods to make this chip more area efficient and error tolerant. One of the techniques that we will implement to realize energy-efficient, sign-aware, and robust deep neural network (DNN) processing is the two transistor two ReRAM (2T2R) technique which uses two transistors and two memristors to realize a single crossbar as shown in figure 6 [7].

Figure 6 2T2R Cell [7]
Table 1 shows the parameters of the chip
Table 1 Performance parameters
|
Performance Parameters of the chip |
|
|
Area |
< 5mm2 |
|
Power consumption |
< 4 Watts |
|
Computational efficiency |
>363.7 GOPs/W |
|
Operating frequency |
1.2GHz |
Sharie, Ali, Anirban Nag, Naveen Murali Manohar, Rajeev Balasubramanian, John Paul Strachan, Miao Hu, R. Stanley Williams, and Vivek Sreekumar. "ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars." ACM SIGARCH Computer Architecture News 44, no. 3 (2016): 14-26.
Wang, Queen, Xinmin Wang, Seung Hwan Lee, Fan-Hsian Meng, and Wei D. Lu. "A deep neural-network accelerator based on tiled RRAM architecture." In 2019 IEEE international electron devices meeting (IEDM), pp. 14-4. IEEE, 2019.
Marek, K., Riga, F.O., Khedira, S. et al. On the design and analysis of a compact array with 1T1R RRAM memory element. Analog Integer Circ Sig Process 102, 27–37 (2020).
Ni, Leibniz, Yahoo Wang, Hao Yu, Wei Yang, Chu liang Weng, and Jun Feng Zhao. "An energy-efficient matrix multiplication accelerator by distributed in-memory computing on binary RRAM crossbar." In 2016 21st Asia and +South Pacific Design Automation Conference (ASP-DAC), pp. 280-285. IEEE, 2016.
Tang, Tianqi, Ligue Xia, Boxun Li, Yu Wang, and Huazhong Yang. "Binary convolutional neural network on RRAM." In 2017 22nd Asia and South Pacific Design Automation Conference (ASP-DAC), pp. 782-787. IEEE, 2017.
Zhu, Shenhua, Hanbok Sun, Yujun Lin, Guha Dai, Ligue Xia, Song Han, Yu Wang, and Huazhong Yang. "A configurable multi-precision CNN computing framework based on single bit RRAM." In 2019 56th ACM/IEEE Design Automation Conference (DAC), pp. 1-6. IEEE, 2019.
Zhou, Z., P. Huang, Y. C. Xiang, W. S. Shen, Y. D. Zhao, Y. L. Feng, B. Gao et al. "A new hardware implementation approach of BNNs based on nonlinear 2T2R synaptic cell." In 2018 IEEE International Electron Devices Meeting (IEDM), pp. 20-7. IEEE, 2018.
We propose the design of a high-speed accelerator that uses Resistive Random Access Memory (ReRAM) cells to perform analog computation. The accelerator will implement convolution neural networks or deep neural networks. The design is inspired by the reference paper [1]. The design of this accelerator has many advantages over conventional digital accelerators. The architecture yields improvements of 14.8×, 5.5×, and 7.5× in throughput, energy, and computational density respectively, over the state-of-the-art design.
acc